Note
These are my rough notes based on attending CS148. They might contain errors so proceed with caution!
Our goal is to mimic human vision in a virtual world. We do this by:
- Creating a virtual camera and placing it somewhere to point at something.
- Putting a film that contains pixels with RGB values between 0 and 255 into the camera.
- Placing some objects in the world. (geometric modeling, transformations, texture mapping).
- Putting lights in the scene.
- And Finally taking the picture. The light will bounce around the room hitting the objects and back hitting the camera onto the virtual film.
Pupil
What is the role of the pupil in the eye? So we know that the lights goes off every point of an object in every direction and this is why we all see the same point on the same object. We looked at this in the previous lecture. What we didn’t discuss is that without the pupil, this light that is bouncing from every single point on the object, is actually hitting every single cone (or pixel in the camera). The image that we’ll see is just going to be a blurred image averaging all these points. We won’t see any details.
The reason why we don’t see everything as a blurry image is the pupil (or the aperture in the camera). The pupil’s rol is to restrict the light bouncing from all these points on every single object. The pupil will only allow some point, enough to see clearly. Moreover, when the pupil gets small, we’d get a sharper image and as the pupil gets larger, we’d see a blurred image. But the pupil (and the aperture) can’t be too small because otherwise the light will bend as it gets through the tiny point due to the particle/wave length duality. Therefore, it has to be small enough but not too small.
The Camera mimic the human eyes but instead of cones we have mechanical pixels. And instead of the pupil, we have an aperture. Cameras have also complex lens system.
Pinhole Camera
Since this is a virtual world, then we won’t have the light bending issue (particle/wave duality) so we can just use a simple camera model, the pinhole camera, where the aperture is just a single point. Light will go through this one point from an object to a pixel.
Here are some more properties of the Pinhole Camera:
- The images created can’t do stuff like depth of field (not blurry as you go farther).
- Object occlude things that appear behind them.
- more distant objects subtend smaller visual angels and appear smaller
- The image will be an upside version of the real world object.
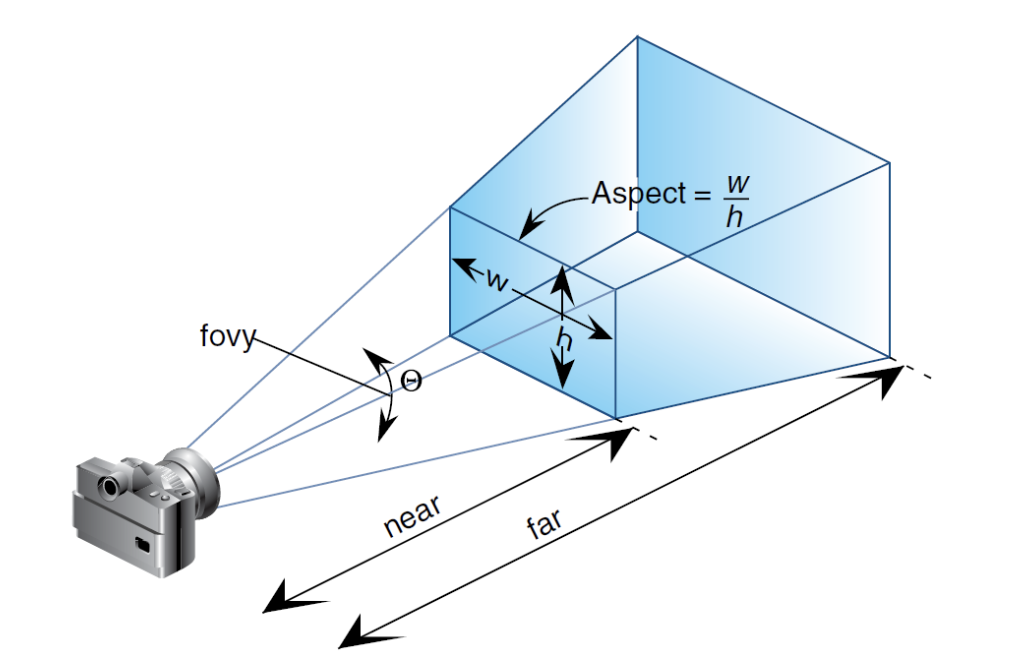
To solve this last issue and make the camera more efficient: - We’ll move the film out in front of the pinhole so that the image is not upside down.
- We’ll only render objects further away from the camera than the film plane.
- We’ll add a clipping plane for efficiency so we don’t have to process every single object knowing that we won’t render it since it’s occluded.
- The volume between the film (front clipping plane) and the back clipping plane is called the viewing frustum.
Objects in the Virtual World
- We’ll model the objects with 3D points. Each object will be a collection of points.
- Objects are created in a reference space that we call the “object space”.
- Once objects are created, we’ll place the objects into the scene. This space is called the “world space”. It’s important to know that we don’t have geometry in the actual space. Instead, we have code that tell us where to place the objects around us via some rigid body motion such as Rotations (3 ways to rotate) and Translate (3 ways to translate) so a total of 6 degrees of freedom. We can also scale the object.
An important question arises here is why create the objects in their object space and then place them via transformations in the virtual world? why not just integrate an object such as a lamp in the virtual world? Because it’s a waste. if the lamp consisted of 100k vertices and the scene needed 100 of these, then we’ll have 10 million vertices just for lamps. Instead we can just create one lamp and then use the transformations that we described to place this lamp 100 times around the scene.
Finally, when we take a virtual picture, points on the object are projected on the 2d film plane which we refer to as a “scene space”. This projection is nonlinear and the source of undesirable distortion.
References
Fundamentals of Computer Graphics, 4th Edition
CS148 Lectures